Book a Demo of MachineMetrics
The leading platform to collect, monitor, analyze, and drive action with machine data. Set up time with a product specialist to learn how we can help your operation.
Ready to empower your shop floor?
Learn More.svg)

Machine failure, once an accepted part of life for manufacturers and OEMs, has met its match with modern technology using IoT devices, the cloud, and edge computing. In order to pre-empt and prevent machine failure, it’s first important to understand what it is and why it happens in an industrial environment.
We can also review existing strategies for dealing with equipment failure including reactive maintenance, diagnostic analytics, and preventive maintenance. In understanding where these strategies fail, we can learn why manufacturers are moving toward predictive maintenance, which resolves the issues of each of its three predecessors.
Here is what we will review if you would like to skip to a particular section:
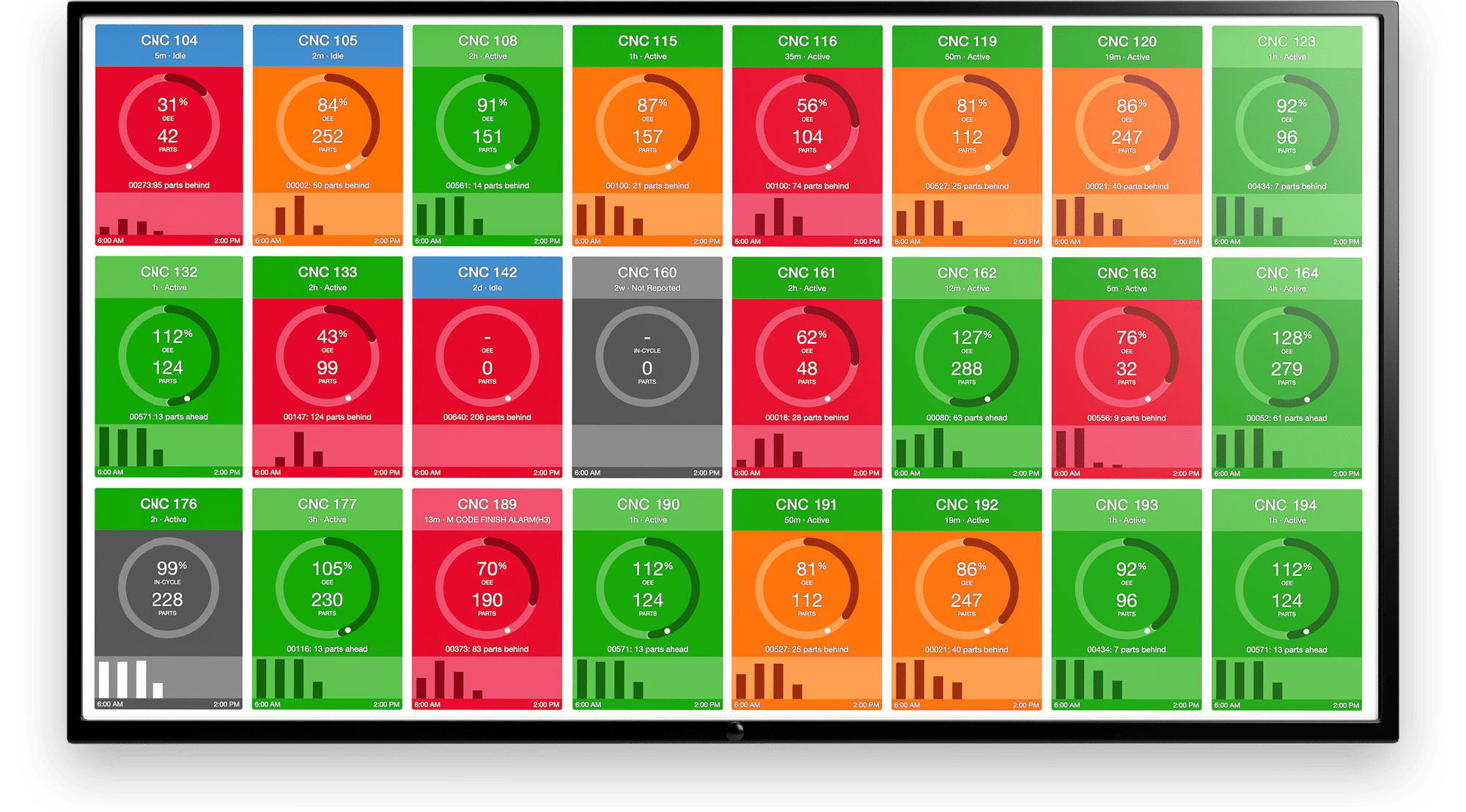
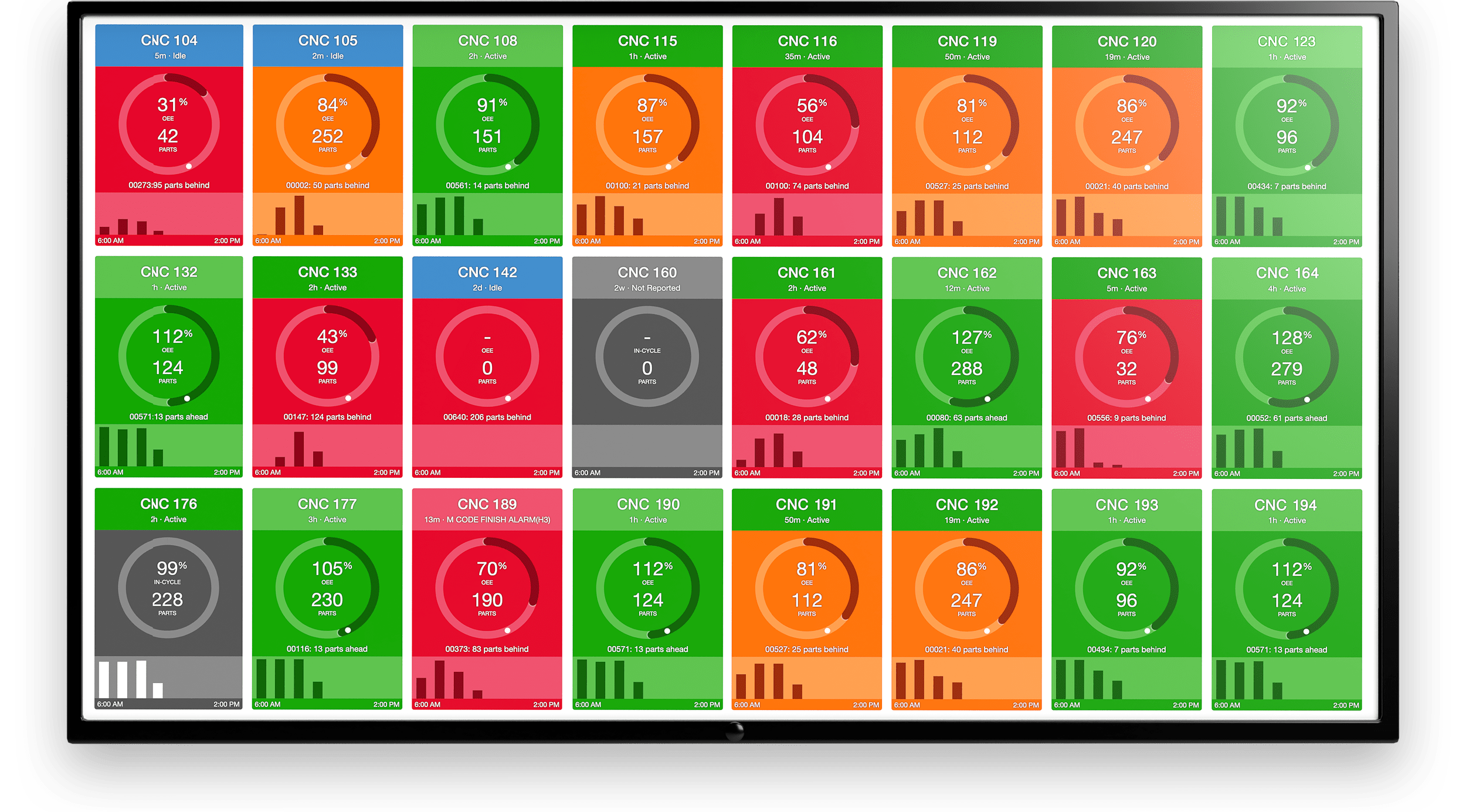
Machine Failure, or Equipment Failure, is any event in which a piece of industrial machinery underperforms, whether entirely or partially, or stops functioning in the way in which it was intended to. The term “machine failure” can encompass differing scenarios and levels of severity, and is often the result of a recurring or undiagnosed machine problem.
A failure, in this context, is not only those critical show-stopper issues that halt production entirely, but also includes any loss of usefulness within a machine. The tolerance threshold for machine failure will vary based on circumstances since all systems degrade and lose effectiveness in some form or another over time. Even perceived minor losses of usefulness can lead to huge resource waste at-scale.
For our purposes, any malfunction that causes a piece of industrial machinery to underperform its duties, whether entirely or partially, is considered a machine failure.
| Success Story: Learn how machine monitoring enabled General Grind to reduce downtime, identify bottlenecks, and increase machine utilization by 100%. Read the full case study. |
What are the Types of Equipment Failure?
Machine failure is a spectrum, and many failures can’t be attributed to a specific point in time. While some are apparent failures that render equipment defunct, others insidiously creep up, while others still steadily drain effectiveness the longer they are left ill-maintained. There are three main classifications of machine failure:
This is what most people think of when they hear machine failure. The production line is humming along when an unexpected (but obvious) breakdown happens. Things like a shattered tool, snapped band, melted wire, etc. fall into this category.
Think of this like a sputtering engine in your production line. It’ll go a little bit, then quit. You start it back up, and it keeps working as intended a little longer, but then it starts failing again. Intermittent failures come and go, usually on their way to a “full” machine failure. These sporadic or random failures can, by their nature, be difficult to identify. Intermittent failures can frequently be prevented with maintenance.
These are the failures you can see over time as a machine’s usefulness takes a steady decline. This includes things like a belt that’s slowly shredding, blades that get duller, pipes that eventually clog with residue buildup. Most gradual failures can be prevented through regular maintenance, armed with an understanding of the expected lifetime of the parts at hand.
Failure starts somewhere. The following are some of the most frequent causes of machine failure and can be used to analyze, prepare, and prevent future instances of malfunction.
If you’ve ever heard the tech support term PEBKAC, the same can be true for industrial equipment. Despite extensive training, humans are still prone to making errors, forgetting important principles from training, laziness, tiredness, and plain old forgetfulness. Sometimes misuse and abuse of equipment by machine operators is to blame for failure. This can also include simple accidents, like dropping a piece of equipment.
This can be too little maintenance, but it can also be too frequent maintenance that leads to machine failure. Maintenance that happens too infrequently can let problems go by unnoticed which can then lead to a domino effect of failure, but frequent maintenance, essentially, introduces chaos into the system each time. Whenever a technician opens up a piece of machinery, there is always the potential for risk and for failure—whether that’s breaking a panel, losing a screw, accidentally jiggling a wire the wrong way, or stripping a bolt. Each of these small incidents can create a new machine problem that increases the likelihood of eventual machine failure. The more often equipment is touched, the more these risks accumulate.
This cause of industrial machine failure includes things like bearing failure, metal fatigue, corrosion, misalignment, and general surface degradation.
If operators are pushed as hard as the equipment and production goals are so tight that they feel like they can’t take a minute to breathe or to resolve an issue safely and to completion, then failures are inevitable. “Band-aid fixes” eventually wear-out, and a widespread culture of quick-and-dirty resolutions can lead to compounding problems and massive machine failure headaches down the line (ultimately resulting in lower overall production, in most cases).
There are multiple strategies you can use to prevent equipment failure, and choosing the right one depends on the criticality of the machine, the predictability of its failures, and the budget and monitoring infrastructure available. The following methods to handle machine failure in an industrial environment are listed from least to most complex.
This is the traditional maintenance paradigm. When it breaks, we fix it. It doesn’t prevent the machine from failing so much as it offers a route to resolving the problem once the malfunction occurs.
This requires a little more digging. Within this maintenance structure, machine data and root cause analysis are deployed to determine why the machine failed in the first place. This information can then be used within a preventive maintenance strategy.
Preventive maintenance includes regularly inspecting machines prior to use, establishing and sticking to a maintenance schedule, regularly replacing components before their average lifespan is over, and anything that tries to ward off the failure before it happens. Think of it like changing the oil in your car every few thousand miles. We don’t wait until the oil is muck and has clogged the rest of our equipment, we just preemptively, preventively, maintain it based on our expectations of when failure would otherwise occur.
Predictive maintenance uses past machine performance to model asset behavior. With enough data, algorithms can work to predict equipment failures based on real-time data off of machines that are IoT-connected. This means that preventive maintenance tasks don’t happen unnecessarily—like replacing perfectly good parts—but instead are based on a deeper and more customized analysis of when failure is impending or most likely to occur.

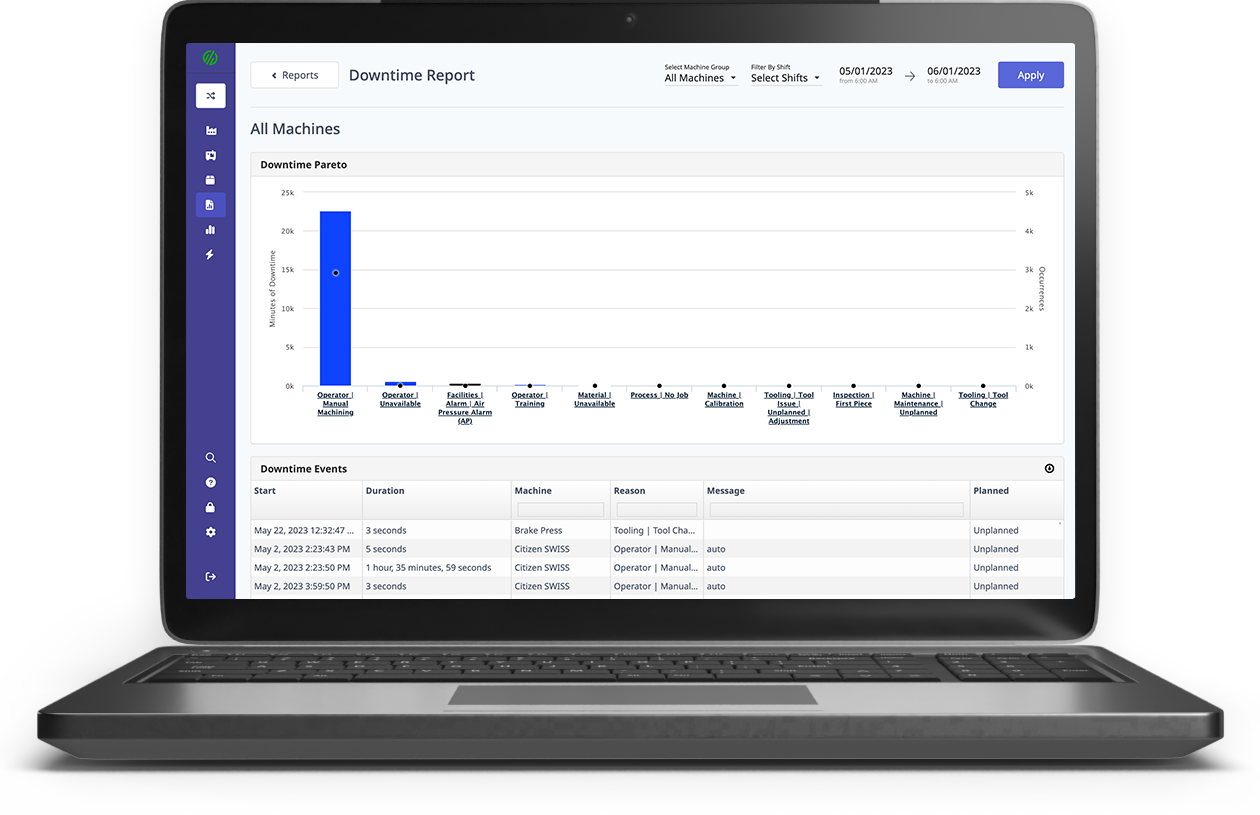
IoT devices offer unprecedented insight to manufacturers and OEMs thanks to the data they provide. IoT-connected machinery can operate within an intelligent network that monitors machine data to identify bottlenecks, notify operators of impending failures, and—when paired with machine learning— even offer suggestions for next actions based on KPIs, e.g. “Should we stop the machine for ten minutes to replace this bit and proceed at normal speed? Would we derive greater value from running the machine at 80% capacity for the next two hours, leaving it with only a 10% chance of complete failure vs. the 60% failure likelihood during the same period when running at 100% capacity?”
The real boon of IoT vs. more traditional data-gathering and analytics methods is its real-time collection capacity. While historical data can offer great insight for preventive maintenance strategies, IoT-enabled predictive maintenance offers a competitive edge to manufacturers by increasing uptime, reducing resource waste, and providing strategic insights that can extend beyond maintenance schedules into process optimization and more. Plus, IoT-connected machinery has the potential to utilize the cloud for deep, rich analysis as well as edge computing for lightning-fast insights, even in secure and air-gapped environments.
Ready to empower your shop floor?
Learn More
.png?width=1960&height=1300&name=01_comp_Downtime-%26-Quality_laptop%20(1).png)



.gif)


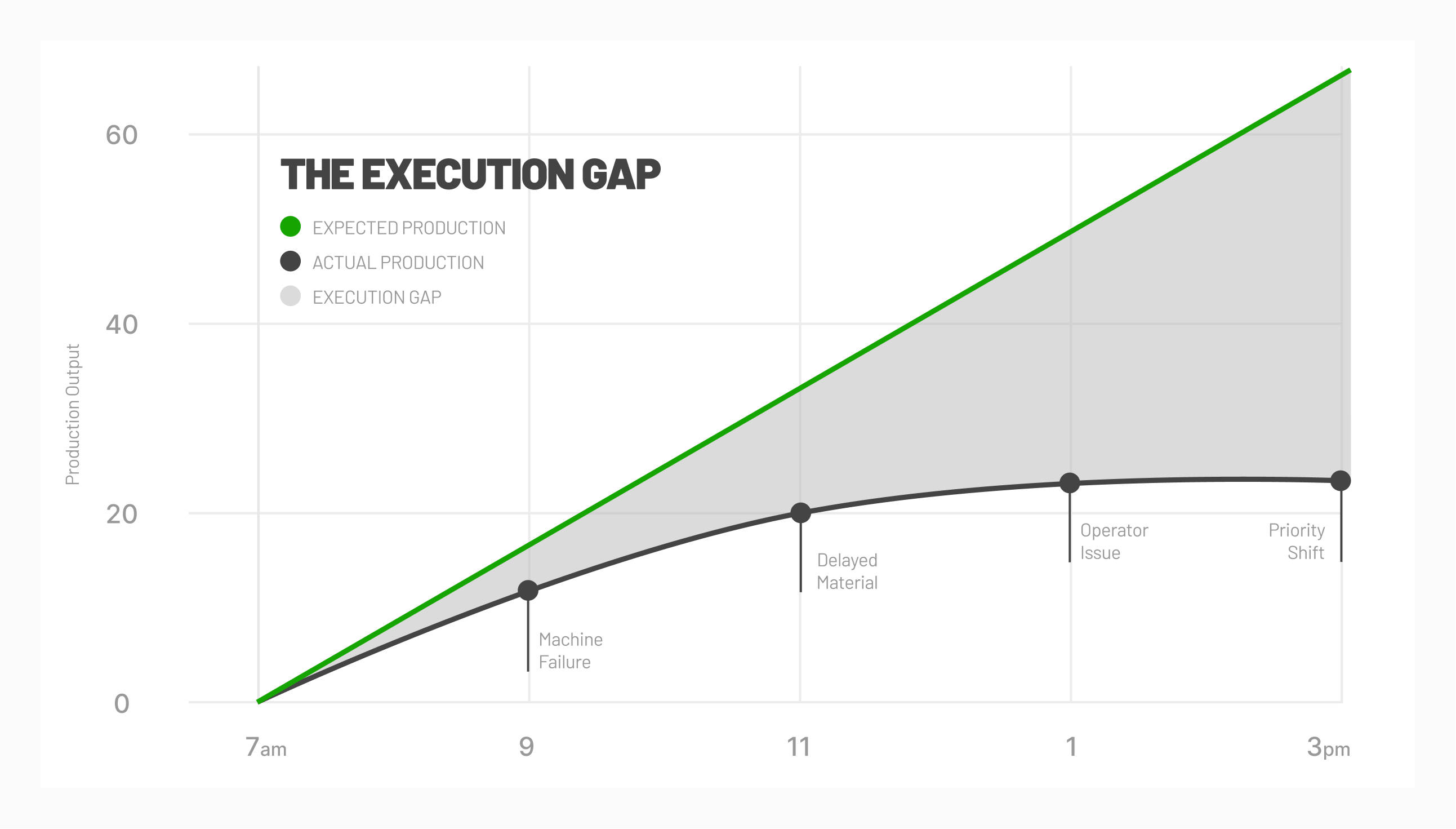

Comments