Book a Demo of MachineMetrics
The leading platform to collect, monitor, analyze, and drive action with machine data. Set up time with a product specialist to learn how we can help your operation.
Ready to empower your shop floor?
Learn More.svg)

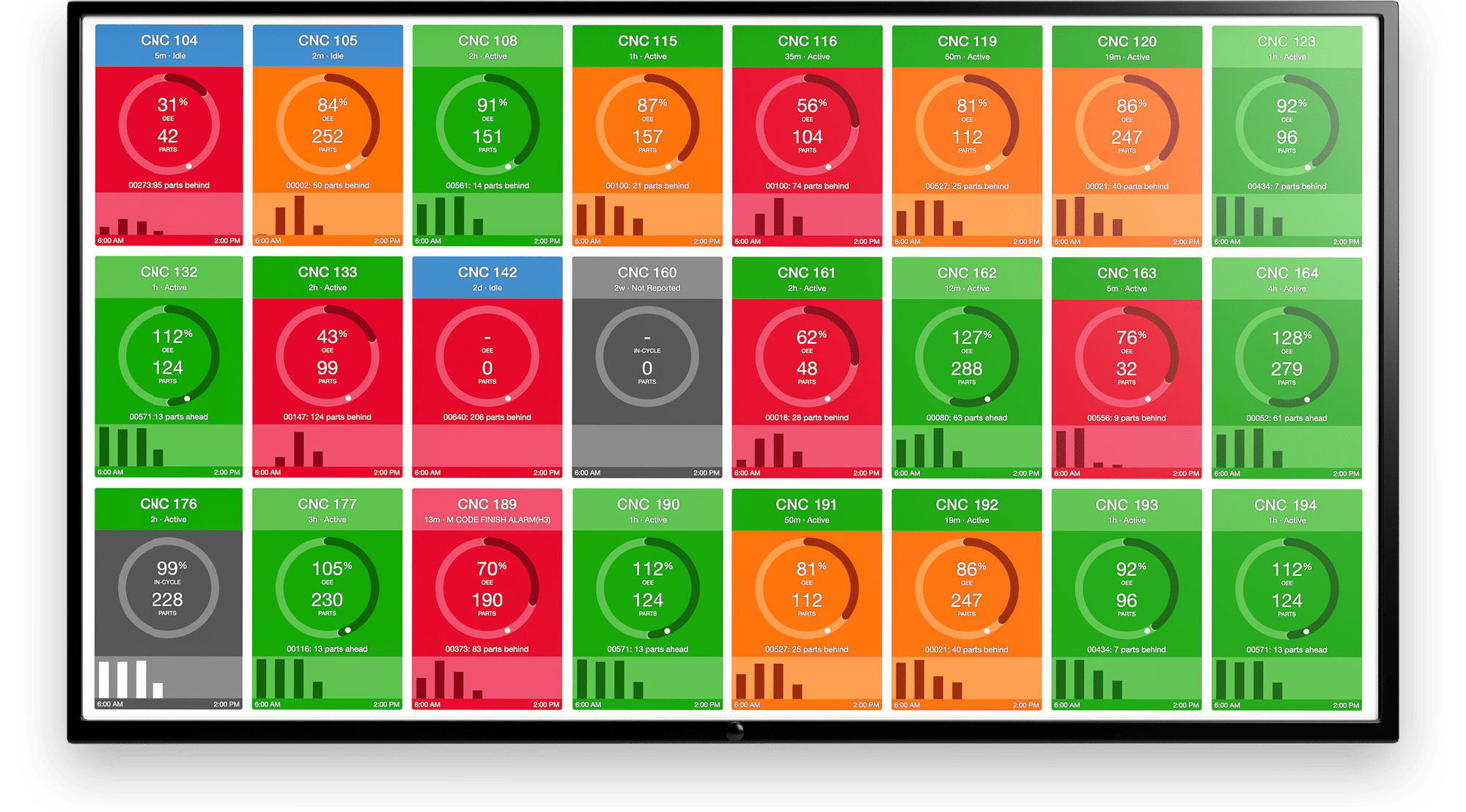
In the world of Computer Numerically Controlled (CNC) machining, many operators struggle to keep their machines on schedule and running efficiently. Unanticipated events can plague machine performance, and a significant portion of these surprises result in costly repairs with a high opportunity cost. Machine tools can cost upwards of a million dollars, with raw materials and labor adding significant variable cost per hour as well. Downtime is disruptive, expensive, and downright frustrating
A Mazak Integrex I-150 Machining Center. Very cool. Much orange. So advance.
We realized this was a huge problem for our customers, and that just monitoring their machine performance wasn’t enough. It became critical to try and leverage our database containing billions of data points of machining activity to predict these breakages and send alerts to operators beforehand.
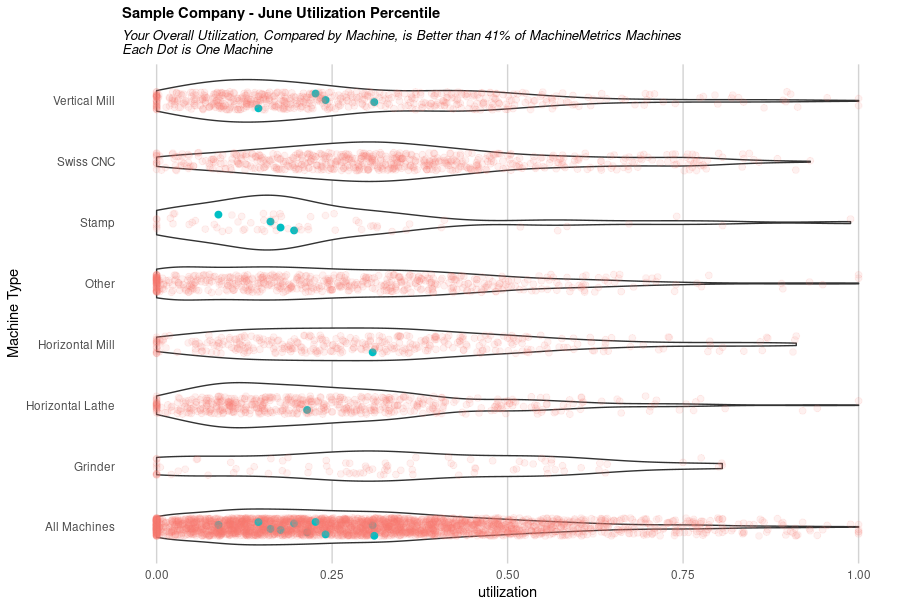
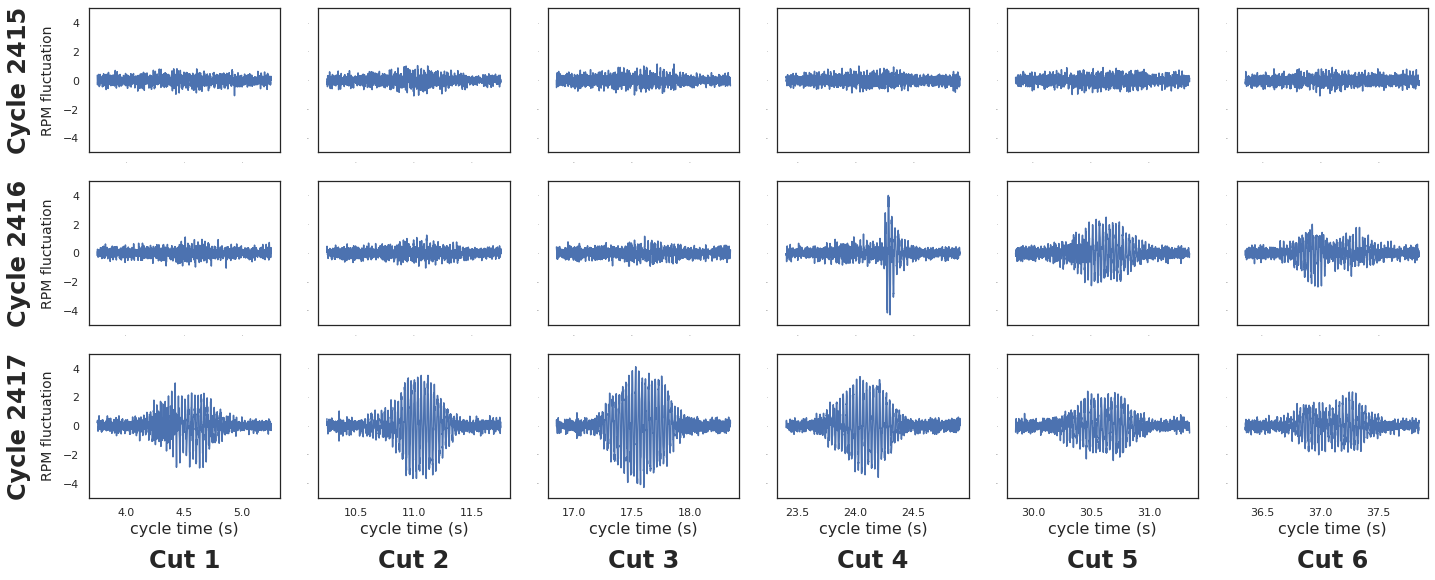
Feedback from industry experts indicated that before a machine breaks, it often behaves in an unusual way. However, it’s difficult to quantify what ‘unusual’ actually is in a rigorous way, as benchmarks may vary from part to part. Industry has developed systems where machine operators can establish strict tolerances that activity should fall between.
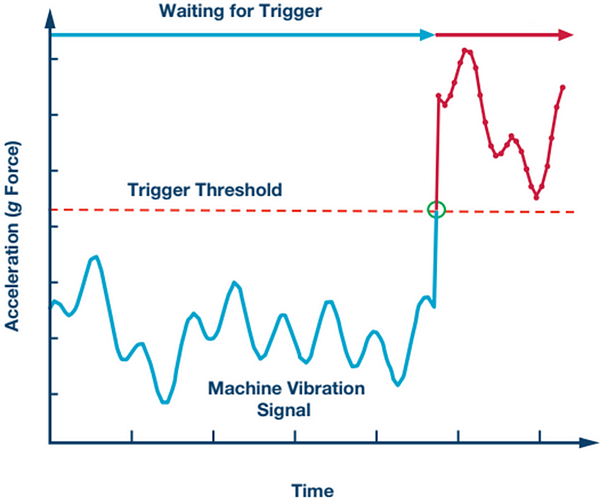
Operators can set the machine to alarm whenever it surpasses x% of rated temperature, vibration, or other metrics. Unfortunately, this must be done manually and requires reprogramming whenever the material type or part being made changes. This is because different parts have different tolerances and fundamentally different manufacturing profiles.
This adds significant cost to the process, taking up valuable personnel resources. We’ve developed an automated way to detect anomalies and save costs on shattered tools and broken dreams. Lack of unified data and lack of computing power have been the major barriers to an automated solution thus far, but MachineMetrics is in the unique position of gathering streaming data from thousands of different machines across hundreds of diverse companies, allowing us to mine a rich array of data sources for our algorithms.
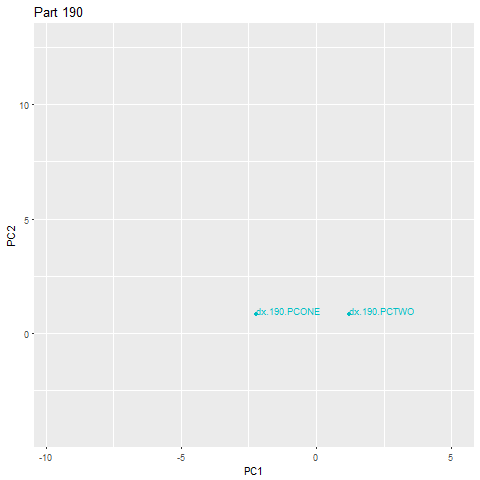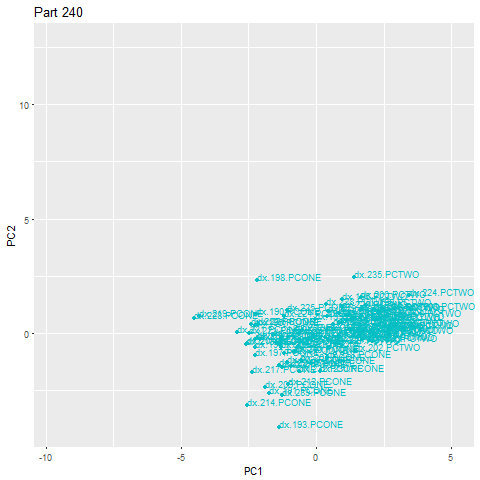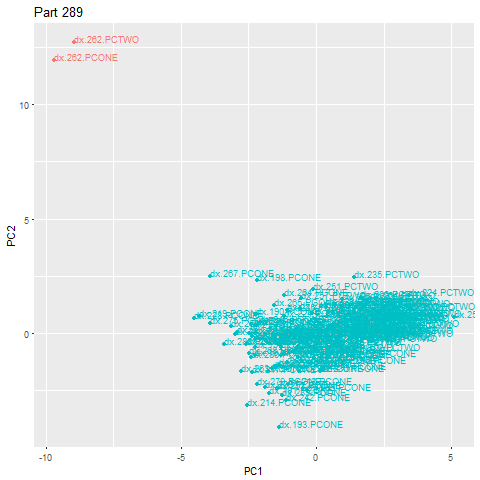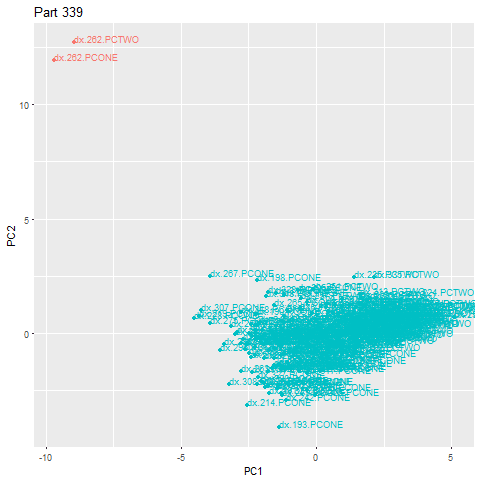
Our patent pending anomaly-detection algorithm is able to tell when a machine is in an inherently different state than a pre-established baseline. We leverage unsupervised machine learning to learn this pre-established baseline.

Unsupervised learning does not require labeled data or manual work to find structure in data. Through intelligent algorithms, it infers the organization of the data and constructs a model of the problem independently of human supervision.
Applied to machining, it means humans do not need to constantly monitor or oversee the process of setting thresholds of operation. Rather, the algorithm learns for itself what tolerances should be, giving customized requirements for each and every part type being machined. We measure the intrinsic qualities of what the machine is doing while making a part, and compute an acceptable range of machining. When the machine’s intrinsic signature falls outside that range, we can raise a flag.
There were challenges to overcome in doing this, but by breaking down the task methodically into smaller pieces, the goal was ultimately achievable. In this series, we present a novel process combining domain knowledge, machine learning, and new ways of looking at the data to autonomously monitor machine anomalies. We leverage the MTConnect-like data (a machine data standard) that MachineMetrics collects through the relays and controls of a machine. This data does not contain:
It does contain:
Our contribution is a way to perform anomaly detection using only measures that are imperative to the operation of the machine, and therefore largely universal across all machines. This saves cost on any extraneous sensors that previously needed to be installed for predictive maintenance, and eliminates the need to deal with the tuning and variance involved with after-market sensor installations. Our methods can also be used to deal with data-scarce environments, and for organizations looking to reduce their data-stream storage and processing costs.
Ready to empower your shop floor?
Learn More
.png?width=1960&height=1300&name=01_comp_Downtime-%26-Quality_laptop%20(1).png)




Comments